
I've been writing concurrent Java for a long time, and every team I've worked on has eventually run into the same thing: a thread leak that nobody can trace, an executor that's still running tasks ten minutes after the request that started them returned, a test that's flaky because of a race nobody can pin down.
Structured concurrency fixes the category of problems that traditional executors leave on the table. Java 26's JEP 525 brings it to the sixth preview, with two focused changes: a new onTimeout callback on Joiner, and a cleaner return type for the most common joiner. It's not finalized yet, but it's close, and the API is stable enough to use seriously in projects that can run with --enable-preview.
This post covers what structured concurrency actually is, what changed in this preview, and how I'm using it with virtual threads in real code.
What is structured concurrency in Java 26?
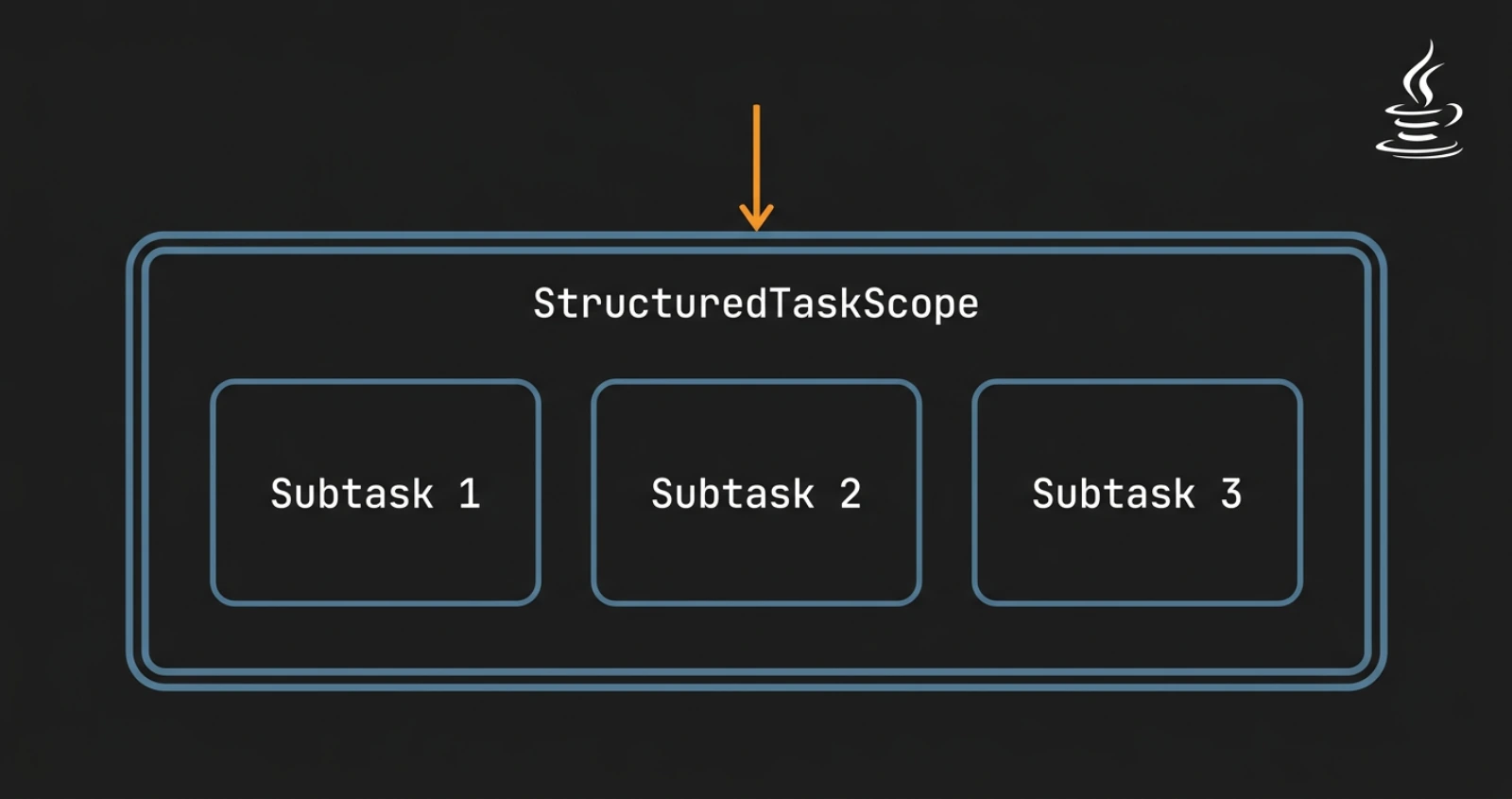
Structured concurrency in Java 26 is an API that confines the lifetime of a group of concurrent subtasks to a single lexical scope, ensuring every subtask is either complete or cancelled when the scope exits.
The principal class is StructuredTaskScope in java.util.concurrent. You open a scope with try-with-resources, fork your subtasks inside it, join the scope as a unit, and the scope handles the rest. If one subtask fails, the scope can cancel the others. If you exit the scope without joining, you get an error rather than orphaned threads.
Here's the simplest case:
try (var scope = StructuredTaskScope.open(
Joiner.<String>allSuccessfulOrThrow())) {
Subtask<String> userTask = scope.fork(() -> fetchUser(userId));
Subtask<String> orderTask = scope.fork(() -> fetchOrders(userId));
List<String> results = scope.join();
return new UserView(results.get(0), results.get(1));
}Two subtasks, each running on its own virtual thread, both have to succeed for the scope to return. If fetchUser throws, the scope cancels fetchOrders and propagates the exception. If fetchOrders is still running when fetchUser succeeds, the scope waits for both. There's no thread that survives past the closing brace.
Compare that to the unstructured version with an ExecutorService:
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
Future<String> userFuture = executor.submit(() -> fetchUser(userId));
Future<String> orderFuture = executor.submit(() -> fetchOrders(userId));
try {
String user = userFuture.get();
String orders = orderFuture.get();
return new UserView(user, orders);
} catch (Exception e) {
userFuture.cancel(true);
orderFuture.cancel(true);
throw e;
} finally {
executor.shutdown();
}That's seven lines of plumbing for a two-task fork-join. The structured version is three.
What changed in the sixth preview?
JEP 525 introduces two API refinements: an onTimeout() callback on the Joiner interface, and a cleaner return type for Joiner.allSuccessfulOrThrow().
Why does the new onTimeout joiner method matter?
onTimeout() lets a custom Joiner react to a timeout and return a partial or fallback result rather than throwing. In earlier previews, hitting a timeout always meant an exception. That worked for hard deadlines, but it didn't fit the patterns that real systems use.
A common case: you have three downstream services to call. Two of them respond in 200ms. The third one is slow and you'd rather return a partial response than wait. With onTimeout(), you can build a Joiner that returns whatever subtasks succeeded by the deadline:
public class FirstNCompleteJoiner<T> implements Joiner<T, List<T>> {
private final List<T> results = new CopyOnWriteArrayList<>();
private final int target;
public FirstNCompleteJoiner(int target) {
this.target = target;
}
@Override
public boolean onComplete(Subtask<? extends T> subtask) {
if (subtask.state() == Subtask.State.SUCCESS) {
results.add(subtask.get());
}
return results.size() >= target;
}
@Override
public List<T> result() {
return List.copyOf(results);
}
@Override
public List<T> onTimeout() {
return List.copyOf(results);
}
}The Joiner accumulates successful results, finishes early once it has target of them, and returns whatever it has if the timeout fires before that. Without onTimeout(), the third path would have thrown.
This is the kind of pattern you can't express cleanly with a try/catch around the join call, because by the time you catch the exception, the partial results are gone.
What's the new return type for allSuccessfulOrThrow?
Joiner.allSuccessfulOrThrow() now returns a List<T> directly from scope.join() instead of a Stream<Subtask<T>>. The fifth preview required you to map the stream to extract values:
// Old (Java 25, fifth preview)
Stream<Subtask<String>> subtasks = scope.join();
List<String> values = subtasks.map(Subtask::get).toList();
// New (Java 26, sixth preview)
List<String> values = scope.join();The old version was technically more flexible because Subtask carries state metadata. In practice, every codebase I've seen calls .get() on every subtask anyway, so the indirection was pure friction. The new return type matches what the common case actually needs.
How do you use StructuredTaskScope in production code?
The factory method to use is StructuredTaskScope.open(Joiner). You pick a Joiner based on what your task semantically needs. The built-in joiners cover the most common patterns.
Joiner.allSuccessfulOrThrow(): every subtask must succeed. Returns a List of results in fork order. If any subtask fails, all others are cancelled and the exception propagates.
Joiner.anySuccessfulResultOrThrow(): race the subtasks. The first successful result wins, the rest are cancelled. If all fail, you get the last failure. Useful for redundant fetches: query two replicas, take whichever responds first.
Joiner.awaitAll(): wait for all subtasks to complete, regardless of outcome. You inspect each Subtask's state afterward to decide what to do. Useful when you want partial results even on failure.
Custom joiners (like the timeout-aware one above) handle the cases the built-ins don't cover.
A real example from a service I'm working on: fetching an order summary that needs a user record, the user's recent orders, and pricing data. All three from different services. If any fails, the whole request fails, but I don't want to wait for the slow ones in series.
public OrderSummary getOrderSummary(String userId, String orderId, Duration timeout)
throws InterruptedException {
try (var scope = StructuredTaskScope.open(
Joiner.<Object>allSuccessfulOrThrow(),
cf -> cf.withTimeout(timeout))) {
Subtask<User> userTask = scope.fork(() -> userService.fetch(userId));
Subtask<List<Order>> ordersTask = scope.fork(() -> orderService.fetch(userId));
Subtask<Pricing> pricingTask = scope.fork(() -> pricingService.fetch(orderId));
scope.join();
return new OrderSummary(
userTask.get(),
ordersTask.get(),
pricingTask.get()
);
}
}The cf.withTimeout(timeout) configures the scope to cancel everything if the deadline is missed. The exception type is StructuredTaskScope.TimeoutException, distinct from any failures the subtasks themselves throw, so callers can react differently.
The throughput numbers from rewriting one of our internal aggregation endpoints with this pattern: median latency went from 720ms (sequential) to 280ms (parallel), with no extra thread pool to manage and no executor to shut down on application stop.
How does it work with virtual threads?
StructuredTaskScope uses virtual threads by default for every forked subtask. You don't configure it, you just fork.
That matters because virtual threads are designed for the case structured concurrency is built around: lots of independent I/O-bound subtasks. A platform thread pool that you'd previously size carefully (say, 200 threads for a high-traffic endpoint) becomes irrelevant. You can fork a thousand subtasks inside a scope and the JVM handles it.
The contract: each forked subtask runs on a fresh virtual thread. The thread is owned by the scope, not by an executor that outlives the scope. When the scope closes, every thread it created is gone.
Where this changes the way you write code: you stop reaching for Executors.newFixedThreadPool or ForkJoinPool.commonPool() for application-level fan-out. Those are still useful for genuinely shared work pools (think: a cron job that processes batches), but for request-scoped concurrency, the scope is the better fit.
A pattern I've started using: if a request handler needs to make N parallel calls, I open a scope, fork the calls, and let the scope manage the thread lifecycle. No more thread pool sizing decisions for request-scoped fan-out.
How do you handle errors and partial failures?
Error handling in structured concurrency hangs on which Joiner you choose, and JEP 525's onTimeout callback adds a third axis: timeout-as-success-with-partial-data.
For the all-or-nothing case, Joiner.allSuccessfulOrThrow() does what its name says. Any subtask failure throws on join(), all sibling subtasks are cancelled, and the original exception propagates with the others as suppressed exceptions. You see all of them in the stack trace, which is a huge debugging improvement over CompletableFuture.allOf() where only the first failure surfaces.
try (var scope = StructuredTaskScope.open(
Joiner.<String>allSuccessfulOrThrow())) {
scope.fork(() -> { throw new IOException("primary failed"); });
scope.fork(() -> { throw new SQLException("secondary failed"); });
scope.join();
} catch (StructuredTaskScope.FailedException e) {
Throwable cause = e.getCause();
Throwable[] suppressed = cause.getSuppressed();
// cause is the first failure observed
// suppressed has the others
}For the partial-results case, Joiner.awaitAll() waits for every subtask regardless of outcome and returns nothing. You inspect each Subtask afterward to decide what to do.
try (var scope = StructuredTaskScope.open(Joiner.<String>awaitAll())) {
Subtask<String> primary = scope.fork(() -> primarySource.fetch());
Subtask<String> fallback = scope.fork(() -> fallbackSource.fetch());
scope.join();
if (primary.state() == Subtask.State.SUCCESS) {
return primary.get();
}
if (fallback.state() == Subtask.State.SUCCESS) {
log.warn("Primary source failed, using fallback", primary.exception());
return fallback.get();
}
throw new ServiceUnavailableException("All sources failed");
}This pattern shows up in any system that has a primary and a fallback path. Without structured concurrency, you'd typically run them sequentially (slow when the primary is slow) or kick off both manually and manage cancellation by hand.
The third axis is the new onTimeout callback. With a custom Joiner that returns partial results on timeout, you get a clean way to express "fetch as much as you can in N milliseconds, then return what you have." That's a pattern I've previously had to build with CompletableFuture.applyToEither and explicit timer scheduling, and it was always brittle. The Joiner-based version is something you can read and trust.
One thing to watch out for: the cancellation that the scope triggers on failure isn't instant. It interrupts the threads, but a subtask doing CPU-bound work that ignores interrupts will run to completion. Structured concurrency doesn't change Java's cooperative cancellation model. If you're forking work that doesn't respond to interrupts, the scope won't be able to clean it up promptly.
The fix is the same one you'd apply anywhere: write code that checks Thread.interrupted() periodically, or call into APIs that throw InterruptedException. The scope can ask threads to stop, but it can't force them.
When should you use structured concurrency vs alternatives?
The decision tree I use:
Use structured concurrency when the subtasks share a lifetime with the parent task. Request handlers, batch processors that fan out per-item work, anything where "all subtasks should be done when this method returns" is a hard requirement.
Use a long-lived ExecutorService when the work outlives the request. Background jobs, queue processors, scheduled tasks that run on a cron. The scope model doesn't fit because there's no parent task to close it.
Use CompletableFuture chaining when you need fine-grained composition: this task's output flows into that task, with branching and merging. The scope model is for fan-out and join, not pipelines.
The case where I'd specifically pick structured concurrency over CompletableFuture.allOf(): when error propagation matters. With allOf, a failure in one future doesn't cancel the others. With StructuredTaskScope, it does, by default. That's usually what you want for request-scoped work, and getting it right with CompletableFuture requires manual cancellation logic.
The case where I'd specifically use it over parallelStream(): when the tasks are I/O-bound. parallelStream runs on the common ForkJoinPool, which is sized for CPU work and pinned to platform threads. Forking I/O work onto it backpressures the rest of the JVM. Structured concurrency on virtual threads doesn't have that problem.
What's coming in the seventh preview?
JEP 533 is already in flight as the seventh preview, targeting a future Java release. It refines the API further based on feedback from the sixth preview, but the core shape is stable.
The signal that matters: structured concurrency has been in preview since Java 19. Six previews is a lot, but the API has changed substantially through that period. JEP 525's changes are small and targeted, which suggests the design is settling. I'd expect a final release in the next LTS window.
For Java 26 specifically, this is a feature I'd turn on with --enable-preview for new internal services. The API isn't going to break in ways that hurt, and you get the correctness benefits today. For libraries you publish, I'd still wait for the final release.
The longer-term picture: structured concurrency makes virtual threads usable in a way that traditional thread pools didn't. Virtual threads alone solve the "how do I have a million threads" problem. Structured concurrency solves the "how do I keep them sane" problem. Together they're the first concurrency model in Java that I'd actually recommend without caveats.
For the official spec, see JEP 525: Structured Concurrency (Sixth Preview) and InfoQ's coverage of the timeout joiner refinements. For background on how the API evolved, JEP 505 covered the fifth preview and Bazlur Rahman's deep dive on the timeout changes walks through the design decisions in detail.
Keep Reading
- Virtual Threads in Java 25: A Practical Guide. The thread model that structured concurrency builds on. Read this first if virtual threads are still new to you.
- Java 26 HTTP/3 in HttpClient. The other major Java 26 release feature, useful when you're forking subtasks that hit external services.
- Java 25 Compact Object Headers. Lower-level Java 25 work that pairs with structured concurrency for memory-conscious services.